

Como configurar MC-LAG na Huawei: E-Trunk, Eth-Trunk, LACP e BFD passo a passo.
Aprenda MC-LAG em Huawei, hoje mostramos o porquê do E-Trunk (multi-chassis), quando usar Eth-Trunk (agregação), como ajustar LACP para portas ativas/backup e como o BFD encurta o MTTR. Incluímos recomendações de hash em cenários MPLS e um roteiro de testes para validar o comportamento em falhas.
O link-aggregation (LAG), chamado de Trunk na Huawei (Eth-Trunk quando é Ethernet), é uma tecnologia que combina múltiplas interfaces físicas em uma única interface lógica. Com link-aggregation ganhamos:
- aumento de banda (somatório dos links),
- redundância,
- e convergência rápida em falhas de interfaces/links.
O LAG tradicional é sempre entre dois dispositivos, ponto a ponto:

Tipos de LAG para Huawei
De forma bem simples, na Huawei temos três jeitos principais de usar Eth-Trunk:
- Manual (load-balancing manual)
- Static LACP (LACP estático)
- Manual 1:1 master/backup
No contexto de MC-LAG, o que importa pra nós são basicamente:
- Eth-Trunk manual
- Eth-Trunk em static LACP
Vamos simplificar:
- Você cria o Eth-Trunk, adiciona as interfaces e pronto.
- Todas as interfaces do trunk ficam ativas e encaminhando tráfego.
- Não há negociação com o outro lado, então o “critério” é só a configuração bater (mesmo número de portas, velocidade, duplex etc.).
Static LACP
- Você também cria o Eth-Trunk e adiciona as interfaces, mas o estado delas (ativa ou backup) é decidido pelo LACP.
- O LACP troca mensagens (LACPDUs) entre os dois lados, decide quais links podem fazer parte do LAG e quais serão ativos ou backup.
- Permite M:N (M links ativos, N em backup), limiar mínimo e máximo de links ativos etc.
Como o Trunk balanceia o tráfego
O Eth-Trunk não “soma portas” como uma porta gigante. O equipamento decide por qual membro mandar cada fluxo usando algoritmos de balanceamento. Isso define dois comportamentos principais:
Load-balance baseado em hash
É o padrão na maioria dos roteadores/switches. Funciona assim:
- O equipamento pega campos do pacote (MAC, IP, portas, MPLS etc.).
- Calcula um hash.
- Usa o resultado para escolher um dos links do LAG.
O hash pode usar vários critérios, por exemplo:
src-mac,dst-mac,src-dst-macsrc-ip,dst-ip,src-dst-ip- versões “enhanced” que adicionam mais entropia
- (em cenários MPLS) labels MPLS
Com hash, o modo padrão é per-flow:
- Per-flow: todos os pacotes de um mesmo fluxo vão pelo mesmo link → garante ordem.
- Per-packet: cada pacote pode ir por links diferentes → usa mais banda, mas quebra ordenação (raríssimo em redes SP).
Hash tem uma consequência importante:
Nem sempre distribui banda de forma uniforme.
Dependendo da distribuição dos fluxos (hash), um membro pode ficar no gargalo enquanto outro quase sem tráfego. Isso é normal.
Load-balance dinâmico
Alguns equipamentos suportam o modo dynamic, que monitora a carga instantânea de cada membro e realoca fluxos entre links que estejam subutilizados ou sobrecarregados.
- Mantém ordem dos fluxos,
- Corrige situações onde o hash sozinho deixaria um link “lotado” e outro ocioso,
- É mais eficiente em cenários com poucos fluxos pesados.
Um equipamento que usa esse tipo de balanceamento são os switches da Datacom.
E o que os chips conseguem usar para o hash?
Esse ponto quase ninguém fala, mas é crucial.
Dependendo do ASIC, o roteador pode olhar:
- somente camada 2 + camada 3 (MAC + IP + portas),
- e/ou labels MPLS.
No caso de MPLS:
- Alguns ASICs só conseguem ler o primeiro label do stack.
- Outros conseguem ler os primeiros 3 labels.
- ASICs mais modernos (NPs/NPUs recentes) chegam a ler até o 7º label para gerar entropia no hash.
Isso importa porque:
- Em túneis MPLS, quando todo mundo usa o mesmo label de topo, o hash perde entropia.
- Quando o ASIC não lê profundamente o stack MPLS, vários fluxos podem cair no mesmo link do LAG.
- Hardwares mais modernos conseguem enxergar labels internos (VPN, PW, etc.), dando muito mais diversidade ao hash.
Exemplos práticos:
- VPLS/PWE3 → usar o PW label como entropia (se o chip tiver profundidade suficiente).
- L3VPN → usar o VPN label.
- Tráfego LDP simples → quase sempre hash pobre, pois muitos fluxos compartilham o mesmo label de transporte.
- Utilzar outras técnicas, como o flow-label em serviços.
Em resumo:
Quanto maior a profundidade MPLS que o ASIC enxerga, melhor será a distribuição dos fluxos MPLS no LAG.
O que o LACP faz
O LACP (Link Aggregation Control Protocol, IEEE 802.3ad) é o cara que:
- Negocia se um conjunto de interfaces pode ou não formar um LAG;
- Decide quais interfaces do grupo serão ativas e quais ficam em backup;
- Mantém o estado do LAG: se um link cai, ele pode ativar outro link que estava em standby;
- Detecta problemas de configuração/mismatch (velocidade, duplex, modo etc.) e evita agregar links incompatíveis.
Na Huawei, quando o Eth-Trunk está em static LACP, as interfaces membros:
- Trocando LACPDUs, informam:
- System priority (prioridade do dispositivo),
- System ID (normalmente o MAC do sistema),
- Interface priority,
- Interface number,
- Key (identificador lógico do LAG).
O lado com maior prioridade de sistema (menor valor numérico) vira o Actor. A partir daí:
- O Actor decide quais portas serão ativas (com base na prioridade e nas políticas / limiares);
- O outro lado segue essa decisão para manter consistência.
O que precisa estar “OK” para o LAG subir direito
Pra um Eth-Trunk com LACP funcionar como esperado, alguns pontos precisam estar alinhados entre os dois lados:
- Mesma ideia de LAG/Key (as portas que vão formar o mesmo Eth-Trunk de cada lado);
- Mesma velocidade e duplex nas portas físicas;
- Mesmo tipo de modo LACP (static LACP em ambos os lados);
- Limites coerentes de:
- número mínimo de links ativos (lower threshold),
- número máximo de links ativos (upper threshold), se usados;
- Mínimo de compatibilidade nos timers LACP (rápido/devagar) e modo active/passive (os dois lados em passive não negociam).
O que o LACP faz é usar system priority + system ID + interface priority + interface number para:
- Decidir quem é o Actor;
- Escolher quais portas viram ativas e quais ficam backup.
Entrando no MC-LAG
Até aqui falamos de LAG “normal”, ou seja, entre dois dispositivos apenas.
O MC-LAG (Multi-Chassis LAG) entra quando você quer ter:
- Um único LAG do ponto de vista do cliente (CE),
- Mas na verdade terminando em dois equipamentos diferentes (por exemplo, dois PEs/roteadores de borda).
A ideia é simples:
- Do lado do CE, você enxerga um Eth-Trunk só, com várias portas;
- Fisicamente, essas portas vão para dois PEs diferentes;
- Do lado da operadora, esses dois PEs “se combinam” para parecer um dispositivo único em termos de LACP.
Objetivo principal do MC-LAG:
- Se um PE inteiro morrer (falha de equipamento, reload, etc.),
- O outro PE assume e o CE continua com o mesmo LAG, sem mudar IP, MAC, gateway etc.
É basicamente levar a ideia de redundância do nível de porta/link para o nível de dispositivo.
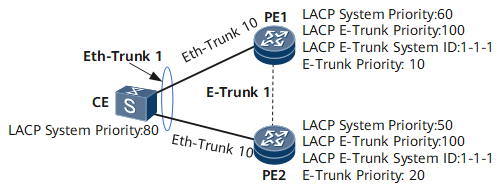
Ativo/ativo vs ativo/backup
Em muitos vendors você encontra MC-LAG em dois sabores:
- Ativo/ativo: os dois dispositivos encaminham tráfego ao mesmo tempo;
- Ativo/backup: apenas um dispositivo é o “dono” do LAG em determinado momento; o outro fica de backup.
Na Huawei, para esse cenário específico com E-Trunk/mLACP, o comportamento é ativo/backup:
- Um lado é o master (ativo),
- O outro lado é o backup (os links ficam lógicos down do ponto de vista do CE),
- Em falha, há switchover do papel de master para o outro equipamento.
MC-LAG na Huawei: E-Trunk vs mLACP
Em Huawei, existem duas formas principais de implementar MC-LAG:
- E-Trunk (Enhanced Trunk)
- mLACP (Multi-chassis LACP)
Ambas têm o mesmo objetivo:
“Enganar” o CE para que ele ache que está falando com um equipamento só, mesmo tendo dois PEs atrás.
A diferença está no mecanismo de controle entre os PEs:
- E-Trunk
- Usa um canal próprio (UDP) entre os PEs, com Hello e timeout;
- Troca informações de estado dos Eth-Trunks que participam daquele E-Trunk;
- Define quem é master e quem é backup com base em E-Trunk priority (menor valor = maior prioridade);
- Controla se o Eth-Trunk local fica up ou down de acordo com o papel (master/backup) e estado do peer.
- mLACP
- Usa ICCP rodando sobre LDP entre os PEs (RG – Redundancy Group);
- Sincroniza configuração e estado LACP via ICCP;
- Define master/backup usando mLACP system priority, system ID e port priority;
- Integra de forma mais “padrão SP” com outras funções de ICCP (VRRP, VPNs redundantes, etc.).
Neste artigo, vamos focar no E-Trunk, que é a forma “clássica” de MC-LAG em muitos cenários de PE–CE.
Como o E-Trunk funciona
Não confundir E-Trunk (a tecnologia de sync entre chassis) com o Eth-Trunk (o link-aggregation em si).
Pense no seguinte cenário:
- CE dual-homed em dois PEs (PE1 e PE2);
- No CE, você cria um Eth-Trunk só, com as portas indo para os dois PEs;
- Nos PEs:
- Você cria o mesmo Eth-Trunk ID em PE1 e PE2;
- Coloca as interfaces físicas correspondentes em cada Eth-Trunk;
- Adiciona esse Eth-Trunk a um E-Trunk com o mesmo E-Trunk ID nos dois lados.
Os PEs então:
- Criam um canal E-Trunk (UDP) entre si (usando IPs de loopback, normalmente);
- Trocam mensagens E-Trunk com:
- E-Trunk ID,
- E-Trunk priority,
- Informações dos Eth-Trunks membros e seu estado;
- Definem quem é master e quem é backup:
- Menor E-Trunk priority ganha,
- Se empatar, menor E-Trunk system ID ganha.
Com isso:
- No master:
- O Eth-Trunk local que participa do E-Trunk fica up e encaminhando.
- No backup:
- O Eth-Trunk equivalente fica em estado de backup (lógico down para o CE ou sem encaminhar tráfego, dependendo do modo);
- O CE vê só um LAG, mas na prática está pendurado em dois PEs, com um deles ativo.
Quando acontece uma falha:
- Se o Eth-Trunk master ou o próprio PE master falhar:
- O backup para de receber Hello ou recebe notificação de falha;
- O backup muda seu Eth-Trunk para master e sobe o LAG;
- O tráfego do CE é desviado para o outro PE.
Opcionalmente, você pode:
- Integrar com BFD entre os PEs pra detecção mais rápida;
- Usar um switchback delay para evitar “ping-pong” de master/backup.
Conectividade CE ↔ PEs com E-Trunk
Alguns pontos importantes de design:
- Do ponto de vista do CE, o E-Trunk é invisível:
- Ele só enxerga um Eth-Trunk LACP normal.
- Nos PEs, se o Eth-Trunk for L3:
- Os Eth-Trunks dos dois PEs normalmente usam o mesmo IP e o mesmo MAC;
- Só o master anuncia rota direta; o backup não anuncia (pra evitar ECMP estranho);
- Muito mais comum é usar Eth-Trunk L2:
- Os PEs participam de uma VLAN/L2 domínio comum;
- O gateway fica em outro equipamento (por exemplo, um core/agg).
Casos de uso
Na topologia abaixo, iremos abordar dois casos de uso para o MC-LAG (existem muitos outros).
- protegendo uma entrega de VPLS para um cliente final (dupla abordagem com redundancia de POPs)
- protegendo um /30 para cliente final (dupla abordagem com redundancia de POPs)
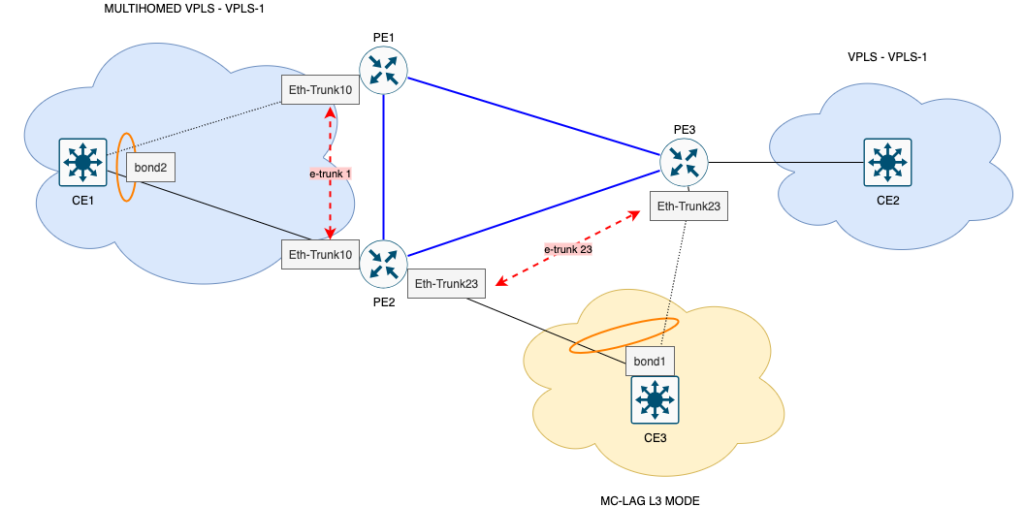
1) MC-LAG protegendo VPLS (camada 2)
No topo do desenho, o CE1 está multihomed em PE1 e PE2 usando MC-LAG, todos na mesma instância VPLS-1.
Do lado da rede, PE1/PE2 fecham a VPLS com o PE3, que entrega o mesmo serviço para o CE2.
- Do ponto de vista do CE1, existe um único LAG para a VPLS.
- Na prática, o tráfego pode sair por dois POPs diferentes (PE1 e PE2).
- Se um POP ou um dos PEs tiver problema, o outro continua entregando a mesma VPLS para o cliente, sem troca de VLAN, MAC ou serviço.
É uma proteção L2 fim-a-fim da VPLS, com redundância de equipamento e de POP.
2) MC-LAG protegendo /30 L3 (camada 3)
Na parte de baixo do desenho, o CE3 recebe um /30 L3 via MC-LAG, dual-homed em PE2 e PE3.
- O CE3 enxerga um único LAG L3, com o mesmo /30, pendurado em dois POPs.
- Somente o PE em estado master anuncia a rota direta para esse /30; o outro fica em backup.
- Em falha de link, PE ou POP, há switchover de master/backup e o /30 continua acessível pelo outro lado.
Configurando o ambiente
Agora que você já conhece todos os conceito por trás do MC-LAG, vamos para o laboratório. Vamos utilizar o ambiente virtual PNETLAB, com a imagem Huawei NE40 V22.
As portas físicas e ligações entre dispositivos estão descritas na topologia abaixo.
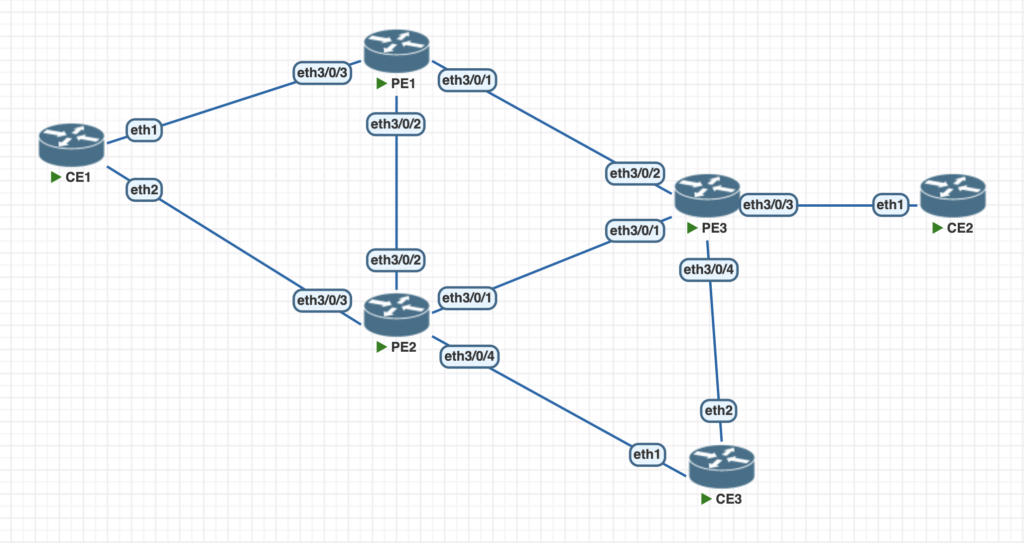
A configuração dos CEs é simples: um mikrotik (ROS 7.6) usando interfaces bonding, com LACP fast (em 1s). O CE3 é simplesmente uma interface física com VLAN.
CE1
# configura o hostname
/system identity set name=CE1
# cria o LAG bond2 usando LACP entre as portas ether1 e ether2
/interface bonding add lacp-rate=1sec mode=802.3ad name=bond2 slaves=ether1,ether2
# adiciona a vlan 10 , utilizada no VPLS, ligada no LAG bond2
/interface vlan add interface=bond2 mtu=1488 name=vlan10 vlan-id=10
# configura o IP na vlan10
/ip address add address=10.10.10.1/24 interface=vlan10 network=10.10.10.0CE2
# configura o hostname
/system identity set name=CE2
# adiciona a vlan 10 , utilizada no VPLS, ligada diretamente na ether1
/interface vlan add interface=ether1 name=vlan10 vlan-id=10
# configura o IP na vlan10
/ip address add address=10.10.10.2/24 interface=vlan10 network=10.10.10.0CE3
# configura o hostname
/system identity set name=CE3
# cria o LAG bond1 usando LACP entre as portas ether1 e ether2
/interface bonding add lacp-rate=1sec mode=802.3ad name=bond1 slaves=ether1,ether2
# adiciona o IP /30 direto na interface bond1
/ip address add address=10.23.23.2/30 interface=bond1 network=10.23.23.0
# configura o gateway default
/ip route add gateway=10.23.23.1A configuração dos PEs compreende as interfaces ponto a ponto, ativas com OSPF, MPLS. Nas interfaces de acesso, as configurações de LAG e de sincronização e-trunk. E na camada de serviços, colocamos o VPLS (VSI) e também o gateway L3 (com o macete do mac-address e mesmo IP).
PE1 – Camada Core
# configura o hostname
sysname PE1
# habilita o bfd
bfd
# configura e ativa o mpls e o l2vpn
mpls lsr-id 1.1.1.1
mpls
mpls l2vpn
mpls ldp
# configura o ospf e ativa a area 0
ospf 1 router-id 1.1.1.1
opaque-capability enable
area 0.0.0.0
# configura a loopback
interface LoopBack1
ip address 1.1.1.1 255.255.255.255
ospf enable 1 area 0.0.0.0
# configura as interfaces fisicas com o /30 e ativando ospf/mpls
interface Ethernet3/0/1
description to_PE3
undo shutdown
ip address 10.1.3.1 255.255.255.0
ospf cost 1000
ospf network-type p2p
ospf enable 1 area 0.0.0.0
mpls
mpls ldp
undo dcn
undo dcn mode vlan
#
interface Ethernet3/0/2
description to_PE2
undo shutdown
ip address 10.1.2.1 255.255.255.0
ospf network-type p2p
ospf enable 1 area 0.0.0.0
mpls
mpls ldp
undo dcn mode vlanServiço MLAG e E-trunk
Aqui neste ponto está o grande diferencial do MLAG. Vamos primeiramente criar um Eth-Trunk comum, e depois associamos ele a uma configuração e-trunk, que faz a mágica do MLAG acontecer.
# cria a Eth-Trunk10
interface Eth-Trunk10
mode lacp-static
lacp timeout fast
# associa a interface ao eth-trunk
interface Ethernet3/0/3
description to_CE1
undo shutdown
eth-trunk 10Com o LAG criado, agora precisamos criar a configuração do e-trunk. Para configura-lo, precisamos:
- do IP de peer remoto ( a sessão é fechada entre loopbacks)
- definir a prioridade entre os roteadores (menor é melhor)
- configurar os timers (em multiplos de 100ms)
- configurar a autenticação para segurança
- adicionar uma descrição ao e-trunk
- configurar o system-id e prioridade do e-trunk (essas configurações que “enganam” o peer remoto para pensar que é o mesmo dispositivo)
No nosso laboratório, iremos fechar entre a loopback do PE1 com o PE2 – estes fazem parte do MLAG na perspectiva do CE1. A prioridade de master será do PE2, com prioridade 5. Os timers configurados são 9 para hello e 30 para hold-timer.
# configura os parametros de system-id e prioridade do e-trunk
lacp e-trunk system-id 00e0-beba-cafe
lacp e-trunk priority 1
# cria a sessao BFD entre os peers PE1 e PE2
bfd hello bind peer-ip 2.2.2.2 source-ip 1.1.1.1
discriminator local 1
discriminator remote 2
# cria o etrunk-1
e-trunk 1
# a descricao
description PE1_to_PE2
# configura a prioridade
priority 10
# diz quais os peers da comunicacao
peer-address 2.2.2.2 source-address 1.1.1.1
# configura timers
timer hello 9
timer hold-on-failure multiplier 30
# autenticacao/senha
authentication-mode enhanced-hmac-sha256
security-key cipher %^%#dX@~~;axSXr!.(&d<4PYE)n7:!hcBBD-`2>JeFa!%^%#
# associa a sessao BFD com o e-trunk
e-trunk track bfd-session session-name helloPor fim, é hora de associar a interface LAG com o e-trunk, criando assim um MLAG na perspectiva do CE1.
# associa o e-trunk ao Eth-Trunk, criando assim o MLAG
interface Eth-Trunk10
e-trunk 1Serviços VPLS
# cria o VPLS chamado VPLS-1
vsi VPLS-1 static
pwsignal ldp
vsi-id 1
mac-withdraw enable
interface-status-change mac-withdraw enable
peer 3.3.3.3
ignore-ac-state
# cria a interface da vlan10 e associa o VPLS
interface Eth-Trunk10.10
vlan-type dot1q 10
l2 binding vsi VPLS-1PE2 – Camada Core
As configurações CORE e VPLS do PE2 são similares as do PE1
Serviço MLAG e E-trunk
# configura os parametros de system-id e prioridade do e-trunk
lacp e-trunk system-id 00e0-beba-cafe
lacp e-trunk priority 1
# cria o lagg e associa a interface fisica de acesso
interface Eth-Trunk10
mode lacp-static
lacp timeout fast
interface Ethernet3/0/3
description to_CE1
undo shutdown
eth-trunk 10
# cria a sessao BFD
bfd hello bind peer-ip 1.1.1.1 source-ip 2.2.2.2
discriminator local 2
discriminator remote 1
# cria o etrunk1 com o PE1
e-trunk 1
priority 5
peer-address 1.1.1.1 source-address 2.2.2.2
timer hello 11
timer hold-on-failure multiplier 33
security-key cipher %^%#tv.DQ.!Y,C7ga=SnUvtMsT84Xld,eBTM\\6fSq#2%^%#
e-trunk track bfd-session session-name hello
authentication-mode enhanced-hmac-sha256
description PE1_to_PE2
# associa o e-trunk ao LAG
interface Eth-Trunk10
e-trunk 1Serviços Gateway redundante
Para o serviço de gateway redundante para o CE3, iremos:
- estabelecer um LAG entre o PE2xCE3 e um lag entre PE3xCE3
- ativar o e-trunk entre PE2 x PE3 no lag criado
- configurar os parametros de system-id e priority do e-trunk
- configurar o mesmo endereço IP e mesmo mac-address na interface Eth-trunk, em ambos roteadores
- adicionar a interface no OSPF
# configura os parametros de system-id e prioridade do e-trunk
lacp e-trunk system-id 00e0-beba-cafe
lacp e-trunk priority 1
# cria o LAG Eth-Trunk23
interface Eth-Trunk23
mode lacp-static
lacp timeout fast
# adiciona a interface ao LAG
interface Ethernet3/0/4
description to_CE3
eth-trunk 23
# cria a sessao BFD entre o PE2 e PE3
bfd peer_r2_r3 bind peer-ip 3.3.3.3 source-ip 2.2.2.2
discriminator local 23
discriminator remote 32
# cria o e-trunk23 entre os roteadores
e-trunk 23
priority 5
peer-address 3.3.3.3 source-address 2.2.2.2
timer hold-on-failure multiplier 30
security-key cipher %^%#tv.DQ.!Y,C7ga=SnUvtMsT84Xld,eBTM\\6fSq#2%^%#
e-trunk track bfd-session session-name peer_r2_r3
authentication-mode enhanced-hmac-sha256
description PE2_to_PE3
# associa o e-trunk ao Eth-Trunk, formando assim o MLAG
interface Eth-Trunk23
e-trunk 23
# finalmente, configura o endereçamento IP, mac e adiciona no OSPF a interface
interface Eth-Trunk23
ip address 10.23.23.1 255.255.255.252
ospf enable 1 area 0.0.0.0
mac-address 00e0-beba-cafePE3 – Camada Core
As configurações CORE do PE3 são similares as do PE1.
Serviços VPLS
Diferente dos PE1 e PE2 que tem um MLAG com o CE, neste caso a comunicação PE3xCE2 ocorre diretamente na interface física com a vlan 10. As configurações de VPLS permanecem iguais, a diferença está nos peers, que fechamos o VPLS com o PE1 e PE2 ao mesmo tempo.
# cria o VPLS e adiciona os PE1 e PE2
vsi VPLS-1 static
pwsignal ldp
vsi-id 1
mac-withdraw enable
interface-status-change mac-withdraw enable
peer 1.1.1.1
peer 2.2.2.2
ignore-ac-state
# habilita a interface com o CE2
interface Ethernet3/0/3
description to_CE2
undo shutdown
# cria a interface vlan 10 e associa ao VPLS
interface Ethernet3/0/3.10
vlan-type dot1q 10
l2 binding vsi VPLS-1Serviços Gateway redundante
# configura os parametros de system-id e prioridade do e-trunk
lacp e-trunk system-id 00e0-beba-cafe
lacp e-trunk priority 1
# cria o LAG Eth-Trunk23
interface Eth-Trunk23
mode lacp-static
lacp timeout fast
# adiciona a interface ao LAG
interface Ethernet3/0/4
description to_CE3
eth-trunk 23
# cria a sessao BFD entre o PE2 e PE3
bfd peer_r3_r2 bind peer-ip 2.2.2.2 source-ip 3.3.3.3
discriminator local 32
discriminator remote 23
# cria o e-trunk23 entre os roteadores
e-trunk 23
priority 5
peer-address 2.2.2.2 source-address 3.3.3.3
timer hold-on-failure multiplier 30
security-key cipher %^%#tv.DQ.!Y,C7ga=SnUvtMsT84Xld,eBTM\\6fSq#2%^%#
e-trunk track bfd-session session-name peer_r2_r3
authentication-mode enhanced-hmac-sha256
description PE3_to_PE2
# associa o e-trunk ao Eth-Trunk, formando assim o MLAG
interface Eth-Trunk23
e-trunk 23
# finalmente, configura o endereçamento IP, mac e adiciona no OSPF a interface
interface Eth-Trunk23
ip address 10.23.23.1 255.255.255.252
ospf enable 1 area 0.0.0.0
mac-address 00e0-beba-cafeValidando as configurações e redundância
MC-LAG entre dispositivos
Na visão do CE1, ele tem duas portas ativas no LAG bond2, sendo a porta ether2 – que fala com PE2 – a principal. A outra fica pronta para uso, mas com as flags de não encaminhar tráfego.

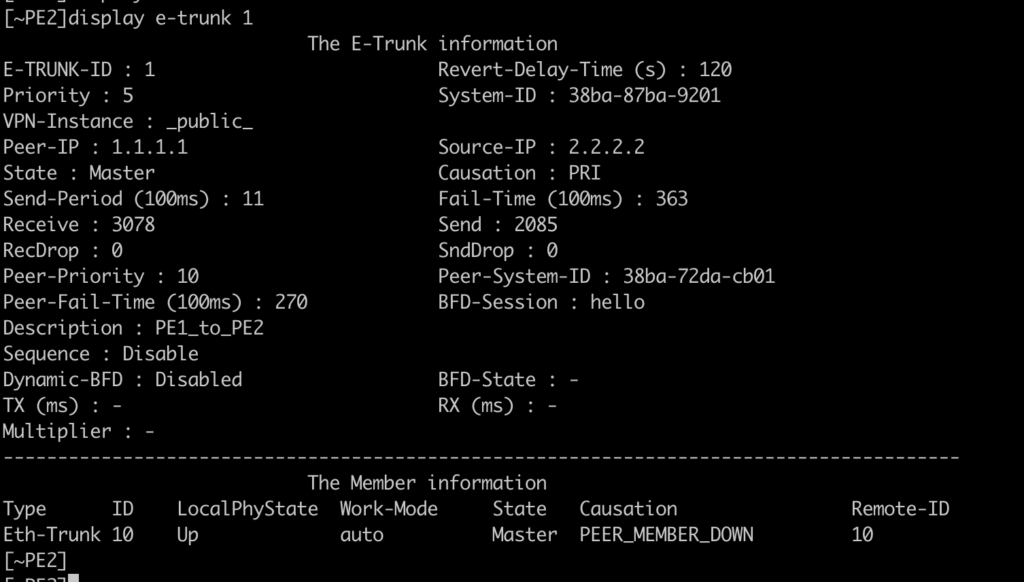
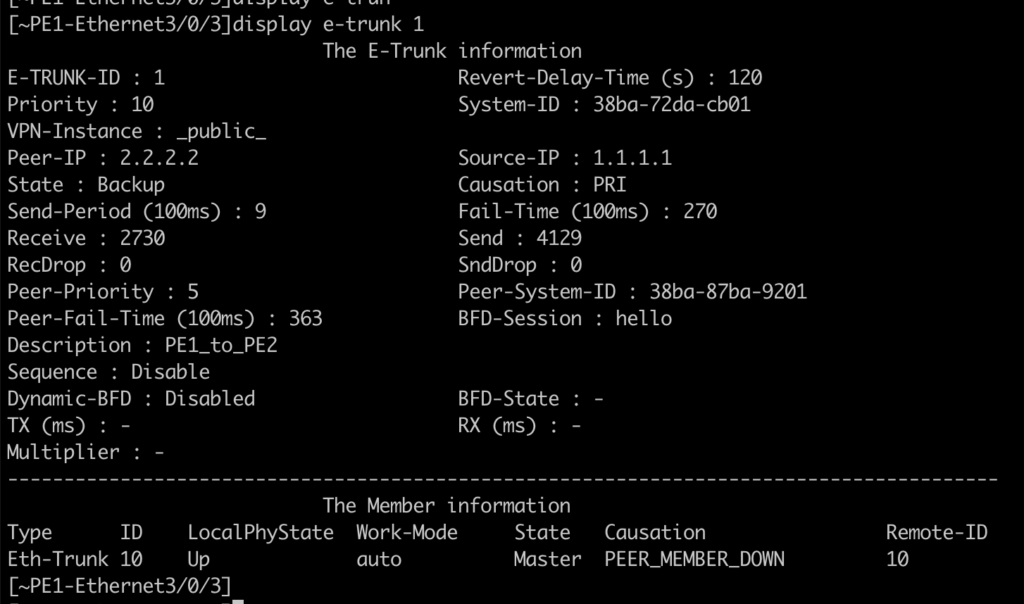
No lado do PE1, ele encontra a Eth-Trunk1 com o estado UP, mas o protocol DOWN, com a causa E-TRUNK DOWN. Isto se deve porque o MLAG é ativo/backup, e com isso o roteador com pior prioridade fica no estado de backup.

Podemos ver que no PE1, o e-trunk está como backup:

Já no PE2, vemos a interface Eth-Trunk 10 como UP. E a interface Eth-trunk10.10 como UP.

Podemos ver que o e-trunk está up, e como master:
Serviço VPLS
Para o teste do serviço VPLS, vamos:
- pingar entre os CEs
- validar por qual interface o tráfego está passando
- derrubar a interface principal no PE2
- verificar que o tráfego imediatamente convergiu para o outro link
Trafego pela ether2, com ping entre os CEs:

Derrubando a interface de acesso no PE2 (simulando um rompimento), e ao mesmo tempo checando a reconvergencia:
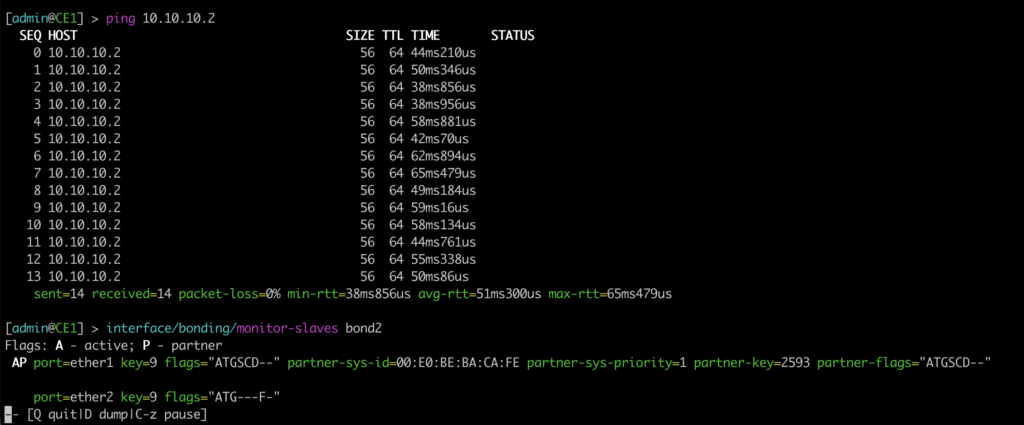
Praticamente sem perdas! O LACP/LAG simplesmente chaveou para o link da ether1 com o PE1. Nesse caso, o e-trunk ficou UP no PE1:
Serviço Gateway redundante
O serviço de gateway redundante pode ser checado diretamente no CE3.
A porta ativa no CE3 é a ether2, ligada no PE3:

Temos ping para o gateway e também para a loopback do PE1. Percaba também o traceroute passando por PE3xPE2xPE1 (caminho preferido por conta de custo manipulado no OSPF).
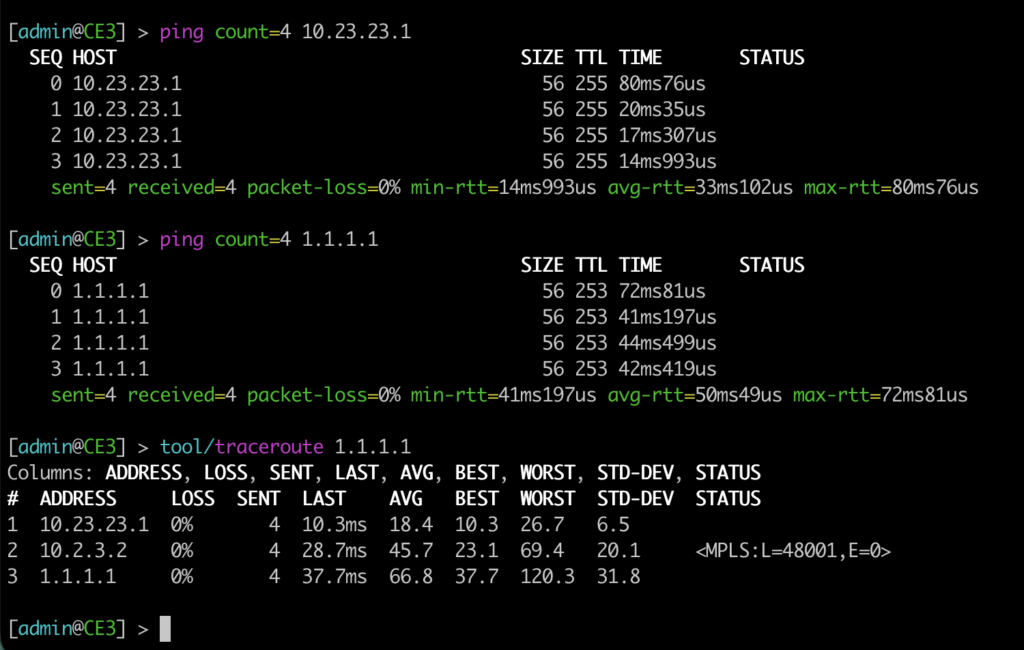
Aqui vamos derrubar a interface física no PE3, ao mesmo tempo que um ping fica rodando no CE2 para a loopback do PE1. E no final vemos a mudança do traceroute.

Mudança do LACP para a porta ether1.

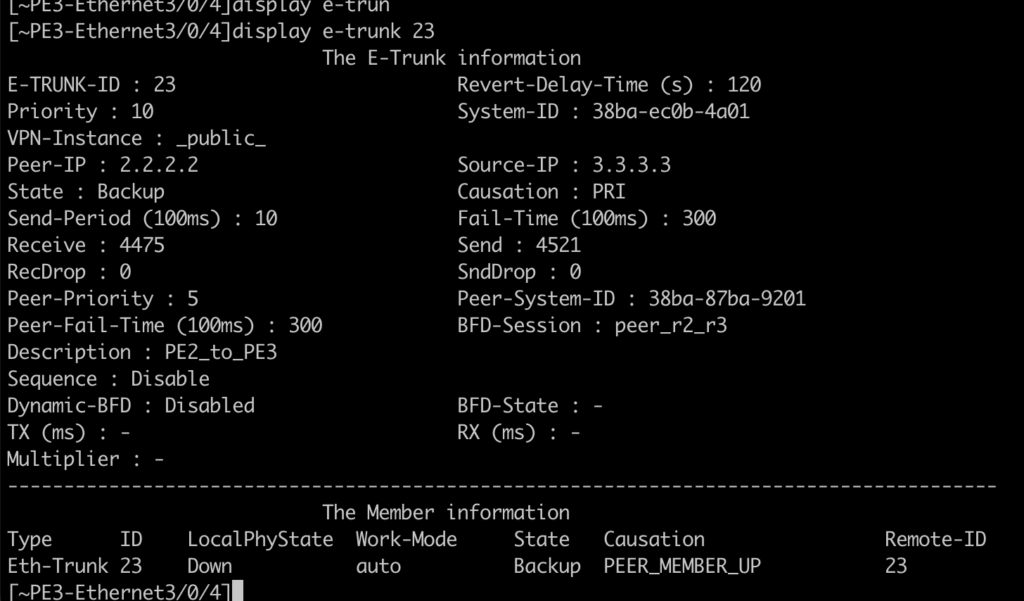
Estado do e-trunk no PE3 e PE2:
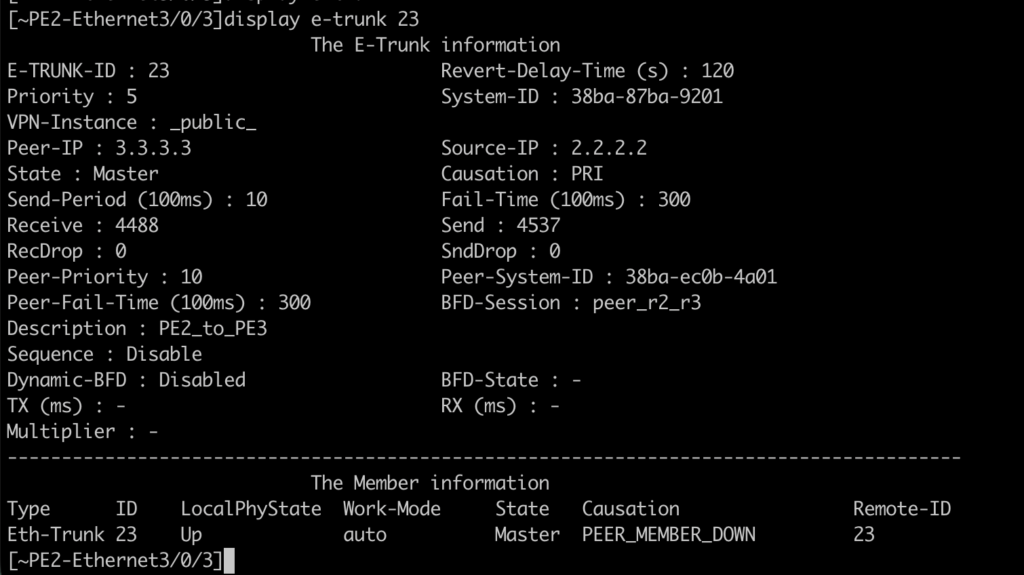
E por quê desta vez não foi “tão” transparente ? Por quê não tivemos o mesmo comportamento do serviço VPLS?
A resposta está em um elemento novo: o roteamento interno para o bloco do gateway. Para este cenário, o roteador que está ativo é quem gera a rota no OSPF:
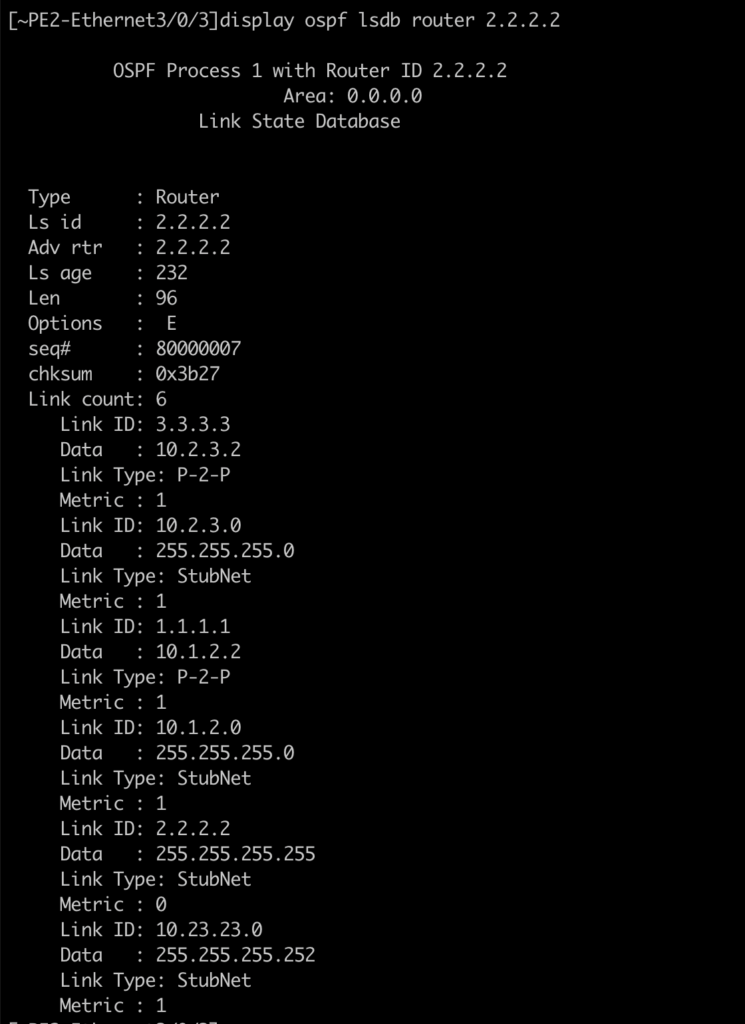
O PE3, que teve a interface colocada em shutdown, não gera a rota:

Então respondendo, o delay se deve porque além de fazer o chaveamento do LACP via e-trunk, toda a rede OSPF teve que recalcular a nova rota para o novo roteador, adicionando alguns segundos na brincadeira (PE3 floodou a rede com o LSA derrubando a rede 10.23.23.0/24, toda a rede processou e recalculou o SPF, e então o PE2 ao reconvergir o e-trunk/lacp, gerou novamente a rede 10.23.23.0/24).
Conclusões
O MC-LAG é muito útil para garantir a alta disponibilidade não só de links, mas também de dispositivos e até mesmo POPs. Ele se mostrou viável para diversos tipos de serviço, tanto de L2 quanto de L3. O protocolo e-trunk da Huawei é muito leve e versátil, e usa mecanismos inteligentes como o BFD para tornar tudo mais rápido. Sua grande desvantagem é que não temos um MLAG Ativo/Ativo, ou seja, sempre um dos circuitos (ou conjunto de circuitos) vai ficar ocioso.
Eaí, já conhecia o MC-LAG? Espero que tenha gostado do artigo, e se precisar de ajuda, a Made4it pode te ajudar. Somos especialistas em redes com alta disponibilidade e segurança.
QUERO TER ALTA DISPONIBILIDADE