

Cómo configurar MC-LAG en Huawei: E-Trunk, Eth-Trunk, LACP y BFD paso a paso.
Aprende MC-LAG en Huawei, hoy te mostramos por qué E-Trunk (multichasis), cuándo utilizar Eth-Trunk (agregación), cómo ajustar LACP para puertos activos/de reserva y cómo BFD acorta el MTTR. Hemos incluido recomendaciones para el hashing en escenarios MPLS y un script de prueba para validar el comportamiento ante fallos.
La agregación de enlaces (LAG), llamada Trunk en Huawei(Eth-Trunk cuando es Ethernet), es una tecnología que combina varias interfaces físicas en una única interfaz lógica. Con la agregación de enlaces ganamos:
- aumento del ancho de banda (suma de enlaces),
- redundancia,
- y convergencia rápida en caso de fallos de interfaz/enlace.
El LAG tradicional es siempre entre dos dispositivos, punto a punto:

Tipos de LAG para Huawei
En pocas palabras, en Huawei tenemos tres formas principales de utilizar Eth-Trunk:
- Manual (equilibrio de carga manual)
- LACP estático
- Manual 1:1 maestro/reserva
En el contexto de MC-LAG, lo que nos importa es básicamente:
- Manual Eth-Trunk
- Eth-Trunk en LACP estático
Hagámoslo sencillo:
- Creas Eth-Trunk, añades las interfaces y listo.
- Todas las interfaces troncales están activas y reenviando tráfico.
- No hay negociación con el otro lado, por lo que el «criterio» es sólo la configuración a batir (mismo número de puertos, velocidad, dúplex, etc.).
LACP estático
- También creas Eth-Trunk y añades las interfaces, pero su estado (activo o de reserva) lo decide LACP.
- LACP intercambia mensajes (LACPDUs) entre las dos partes, decide qué enlaces pueden formar parte del LAG y cuáles estarán activos o respaldados.
- Permite M:N (M enlaces activos, N en reserva), umbral mínimo y máximo de enlaces activos, etc.
Cómo equilibra Trunk el tráfico
Eth-Trunk no «añade puertos» como una puerta gigante. El equipo decide a través de qué miembro enviar cada flujo mediante algoritmos de equilibrado. Esto define dos comportamientos principales:
Equilibrio de carga basado en hash
Es estándar en la mayoría de los routers/conmutadores. Funciona así
- El dispositivo toma campos del paquete (MAC, IP, puertos, MPLS, etc.).
- Calcula un hash.
- Utiliza el resultado para elegir uno de los enlaces LAG.
El hash puede utilizar varios criterios, por ejemplo:
src-mac,dst-mac,src-dst-macsrc-ip,dst-ip,src-dst-ip- versiones «mejoradas» que añaden más entropía
- (en escenarios MPLS) Etiquetas MPLS
Con hash, el modo por defecto es por flujo:
- Por flujo: todos los paquetes de un mismo flujo pasan por el mismo enlace → garantiza el orden.
- Por paquete: cada paquete puede ir por diferentes enlaces → utiliza más ancho de banda, pero rompe el orden (muy raro en redes SP).
El hash tiene una consecuencia importante:
No siempre distribuye uniformemente el ancho de banda.
Según la distribución de los flujos (hash), un miembro puede estar en el cuello de botella mientras que otro casi no tiene tráfico. Esto es normal.
Equilibrio dinámico de la carga
Algunos dispositivos admiten el modo dinámico, que supervisa la carga instantánea de cada miembro y reasigna los flujos entre los enlaces infrautilizados o sobrecargados.
- Mantiene el orden del flujo,
- Corrige situaciones en las que sólo el hash dejaba un enlace «lleno» y otro inactivo,
- Es más eficaz en escenarios con pocos flujos pesados.
Un dispositivo que utiliza este tipo de equilibrado son los conmutadores Datacom.
¿Y qué pueden utilizar los chips para el hashing?
Casi nadie habla de este punto, pero es crucial.
Dependiendo del ASIC, el router puede tener un aspecto:
- sólo capa 2 + capa 3 (MAC + IP + puertos),
- y/o etiquetas MPLS.
En el caso de MPLS:
- Algunos ASIC sólo pueden leer la primera etiqueta de la pila.
- Otros pueden leer las tres primeras etiquetas.
- Los ASIC más modernos (PN/NPU recientes) leen hasta la 7ª etiqueta para generar entropía hash.
Eso importa porque
- En los túneles MPLS, cuando todos utilizan la misma etiqueta superior, el hash pierde entropía.
- Cuando el ASIC no lee en profundidad la pila MPLS, pueden caer varios flujos en el mismo enlace LAG.
- El hardware más moderno puede ver las etiquetas internas (VPN, PW, etc.), lo que da al hash mucha más diversidad.
Ejemplos prácticos:
- VPLS/PWE3 → utilizar la etiqueta PW como entropía (si el chip es lo suficientemente profundo).
- L3VPN → utilizar la etiqueta VPN.
- Tráfico LDP simple → casi siempre hash pobre, ya que muchos flujos comparten la misma etiqueta de transporte.
- Utiliza otras técnicas, como el etiquetado de flujos en los servicios.
En resumen:
Cuanto mayor sea la profundidad MPLS que vea el ASIC, mejor será la distribución de los flujos MPLS en el LAG.
Qué hace LACP
LACP (Protocolo de Control de Agregación de Enlaces, IEEE 802.3ad) es el que:
- Negocia si un conjunto de interfaces puede o no formar un LAG;
- Decide qué interfaces del grupo estarán activas y de cuáles se hará copia de seguridad;
- Mantiene el estado del LAG: si un enlace cae, puede activar otro enlace que estaba en espera;
- Detecta problemas de configuración/desajuste (velocidad, dúplex, modo, etc.) y evita agregar enlaces incompatibles.
En Huawei, cuando Eth-Trunk está en LACP estático, las interfaces miembro:
- Mediante el intercambio de LACPDUs, informan:
- Prioridad del sistema (prioridad del dispositivo),
- ID del sistema (normalmente la MAC del sistema),
- Prioridad de la interfaz,
- Número de interfaz,
- Clave (identificador lógico del GAL).
El lado con mayor prioridad del sistema (valor numérico más bajo) se convierte en el Actor. A partir de ahí
- El Actor decide qué puertos estarán activos (en función de la prioridad y las políticas/umbrales);
- La otra parte sigue esta decisión para mantener la coherencia.
Qué tiene que estar «bien» para que el GAL suba correctamente
Para que un Eth-Trunk con LACP funcione como se espera, es necesario que ciertos puntos estén alineados entre ambos lados:
- La misma idea que LAG/Key (las puertas que formarán el mismo Eth-Trunk a cada lado);
- Misma velocidad y dúplex en los puertos físicos;
- Mismo tipo de modo LACP (LACP estático en ambos lados);
- Límites coherentes de:
- Número mínimo de enlaces activos (umbral inferior),
- Número máximo de enlaces activos (umbral superior), si se utiliza;
- Compatibilidad mínima en temporizadores LACP (rápido/lento) y modo activo/pasivo (los dos lados en pasivo no negocian).
Lo que hace LACP es utilizar la prioridad del sistema + ID del sistema + prioridad de la interfaz + número de interfaz para:
- Decide quién es el actor;
- Elige qué puertos están activos y cuáles tienen copia de seguridad.
Entrar en MC-LAG
Hasta ahora hemos hablado de LAG «normal», es decir, sólo entre dos dispositivos.
MC-LAG (Multi-Chassis LAG) entra cuando lo deseas:
- Un único LAG desde el punto de vista del cliente (CE),
- Pero que en realidad terminan en dos equipos distintos (por ejemplo, dos PEs/routers de borde).
La idea es sencilla:
- En el lado CE, puedes ver un único Eth-Trunk con varias puertas;
- Físicamente, estos puertos van a dos PE distintos;
- En el lado del operador, estos dos PE se «combinan» para parecer un único dispositivo en términos de LACP.
Objetivo principal del MC-LAG:
- Si muere todo un PE (fallo del equipo, recarga, etc.),
- El otro PE toma el relevo y el CE continúa con el mismo LAG, sin cambiar de IP, MAC, pasarela, etc.
Básicamente es llevar la idea de redundancia del nivel de puerto/enlace al nivel de dispositivo.
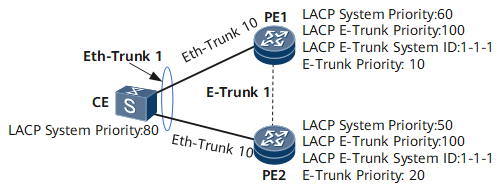
Activo/activo vs activo/reserva
En muchos vendedores puedes encontrar MC-LAG de dos sabores:
- Activo/activo: ambos dispositivos reenvían tráfico al mismo tiempo;
- Activo/respaldo: sólo un dispositivo es el «propietario» del GAL en un momento dado; el otro está respaldado.
En Huawei, para este escenario concreto con E-Trunk/mLACP, el comportamiento es activo/respaldo:
- Un lado es el maestro (activo),
- El otro lado es la copia de seguridad (los enlaces son lógicamente descendentes desde el punto de vista de la CE),
- En caso de fallo, se produce una conmutación del rol de maestro al otro dispositivo.
MC-LAG en Huawei: E-Trunk vs mLACP
En Huawei, hay dos formas principales de implantar MC-LAG:
- Tronco E (tronco mejorado)
- mLACP (LACP Multichasis)
Ambos tienen el mismo objetivo:
«Engañar» al CE para que piense que está hablando con un solo dispositivo, aunque haya dos PE detrás.
La diferencia radica en el mecanismo de control entre los PE:
- Maletero E
- Utiliza un canal propio (UDP) entre los PE, con Hello y timeout;
- Intercambia información sobre el estado de los Eth-Trunks que participan en ese E-Trunk;
- Define quién es el maestro y quién el suplente en función de la prioridad del E-Trunk (valor más bajo = prioridad más alta);
- Controla si el Eth-Trunk local está activo o inactivo según el rol (maestro/de reserva) y el estado del peer.
- mLACP
- Utiliza ICCP corriendo sobre LDP entre los PE (RG – Grupo de Redundancia);
- Sincroniza la configuración y el estado de LACP mediante ICCP;
- Define maestro/respaldo utilizando la prioridad del sistema mLACP, el ID del sistema y la prioridad del puerto;
- Se integra de forma más «estándar SP» con otras funciones ICCP (VRRP, VPN redundantes, etc.).
En este artículo nos centraremos en el E-Trunk, que es la forma«clásica»de MC-LAG en muchos escenarios PE-CE.
Cómo funciona E-Trunk
No confundas E-Trunk (la tecnología de sincronización entre chasis) con Eth-Trunk (la propia agregación de enlaces).
Considera el siguiente escenario:
- CE dual-homed en dos PEs (PE1 y PE2);
- En la CE, creas un único Eth-Trunk, con las puertas que van a ambos PE;
- En los PE:
- Creas el mismo ID de Eth-Trunk en PE1 y PE2;
- Coloca las interfaces físicas correspondientes en cada Eth-Trunk;
- Añade este Eth-Trunk a un E-Trunk con el mismo ID de E-Trunk en ambos lados.
Los EP entonces:
- Crean un canal E-Trunk (UDP) entre ellos (utilizando IPs de loopback, normalmente);
- Intercambian mensajes E-Trunk con:
- ID de tronco electrónico,
- Prioridad del tronco E,
- Información sobre los miembros de Eth-Trunks y su situación;
- Definen quién es el maestro y quién el refuerzo:
- Gana la prioridad E-Trunk más baja,
- Si empata, gana el identificador de sistema E-Trunk más pequeño.
Con esto:
- En el maestro:
- El Eth-Trunk local que participa en E-Trunk está en funcionamiento.
- No hay copia de seguridad:
- El Eth-Trunk equivalente está en estado de reserva (lógicamente caído para la CE o sin reenviar tráfico, según el modo);
- El CE sólo ve un LAG, pero en la práctica está colgado en dos PEs, con uno de ellos activo.
Cuando se produce un fallo:
- Si falla el maestro Eth-Trunk o el propio maestro PE:
- La copia de seguridad deja de recibir Hola o recibe una notificación de fallo;
- La copia de seguridad cambia tu Eth-Trunk a maestro y aumenta el LAG;
- El tráfico del CE se desvía al otro PE.
Opcionalmente, puedes
- Integrar con BFD entre PEs para una detección más rápida;
- Utiliza un retardo de conmutación para evitar el ping-pong maestro/respaldo.
Conectividad CE ↔ PEs con E-Trunk
Algunos puntos importantes del diseño:
- Desde el punto de vista de la CE, el E-Trunk es invisible:
- Sólo puede ver un LACP Eth-Trunk normal.
- En los PE, si el Eth-Trunk es L3:
- Los Eth-Trunks de los dos PE suelen utilizar la misma IP y MAC;
- Sólo el maestro anuncia una ruta directa; el de reserva no lo hace (para evitar ECMP extraños);
- Mucho más habitual es utilizar Eth-Trunk L2:
- Los PE participan en un dominio VLAN/L2 común;
- La pasarela está en otro dispositivo (por ejemplo, un núcleo/agente).
Casos prácticos
En la topología siguiente, cubriremos dos casos de uso de MC-LAG (hay muchos otros).
- proteger una entrega VPLS a un cliente final (enfoque dual con POP redundantes)
- proteger un /30 para el cliente final (enfoque dual con POP redundantes)
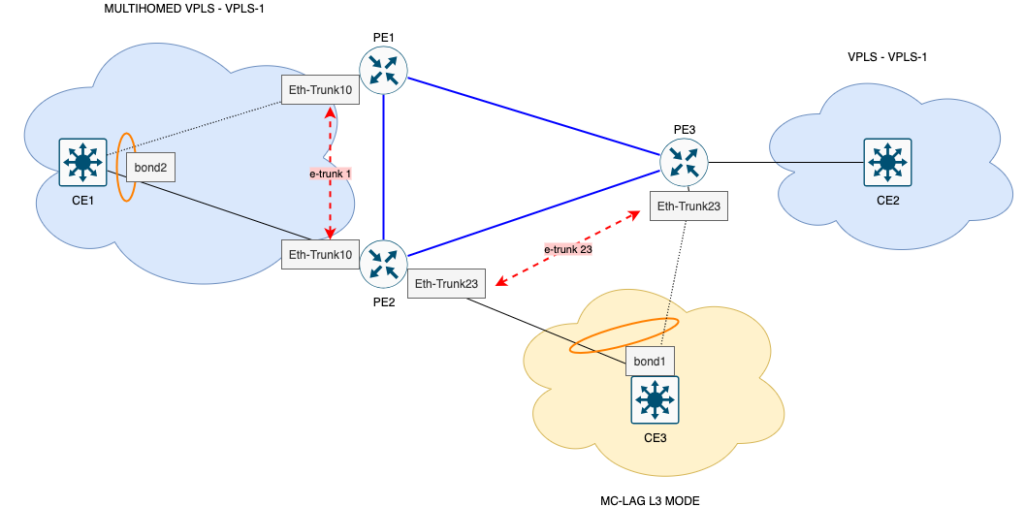
1) MC-LAG que protege VPLS (capa 2)
En la parte superior del dibujo, CE1 está en multihoming con PE1 y PE2 mediante MC-LAG, todos en la misma instancia VPLS-1.
En el lado de la red, PE1/PE2 cierran el VPLS con PE3, que presta el mismo servicio a CE2.
- Desde el punto de vista de CE1, sólo hay un LAG para el VPLS.
- En la práctica, el tráfico puede salir por dos POP distintos (PE1 y PE2).
- Si un POP o uno de los PE tiene un problema, el otro sigue entregando el mismo VPLS al cliente, sin cambiar la VLAN, la MAC o el servicio.
Se trata de una protección L2 de extremo a extremo para el VPLS, con redundancia de equipos y POP.
2) MC-LAG que protege /30 L3 (capa 3)
En la parte inferior del dibujo, CE3 recibe un /30 L3 a través de MC-LAG, dual-homed en PE2 y PE3.
- CE3 ve un único LAG L3, con el mismo /30, colgando de dos POP.
- Sólo el PE en estado maestro anuncia la ruta directa a este /30; el otro está respaldado.
- En caso de fallo de un enlace, PE o POP, se produce una conmutación maestro/respaldo y el /30 sigue siendo accesible desde el otro lado.
Configurar el entorno
Ahora que ya conoces todos los conceptos de MC-LAG, vamos al laboratorio. Vamos a utilizar el entorno virtual PNETLAB, con la imagen Huawei NE40 V22.
Los puertos físicos y las conexiones entre dispositivos se describen en la topología siguiente.
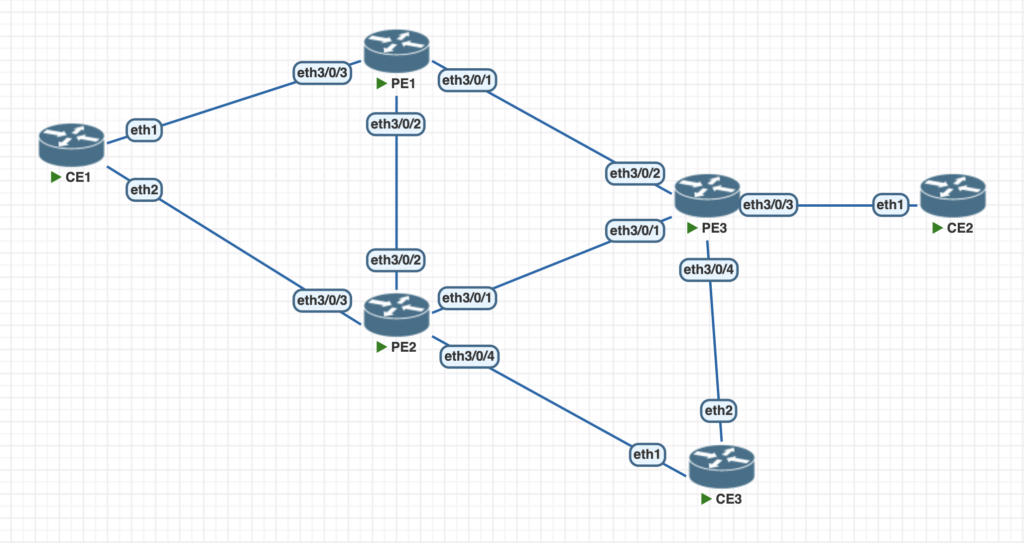
La configuración de los CE es sencilla: un mikrotik (ROS 7.6) que utiliza interfaces bonding, con LACP rápido (en 1s). CE3 es simplemente una interfaz física con una VLAN.
CE1
# configura o hostname
/system identity set name=CE1
# cria o LAG bond2 usando LACP entre as portas ether1 e ether2
/interface bonding add lacp-rate=1sec mode=802.3ad name=bond2 slaves=ether1,ether2
# adiciona a vlan 10 , utilizada no VPLS, ligada no LAG bond2
/interface vlan add interface=bond2 mtu=1488 name=vlan10 vlan-id=10
# configura o IP na vlan10
/ip address add address=10.10.10.1/24 interface=vlan10 network=10.10.10.0CE2
# configura o hostname
/system identity set name=CE2
# adiciona a vlan 10 , utilizada no VPLS, ligada diretamente na ether1
/interface vlan add interface=ether1 name=vlan10 vlan-id=10
# configura o IP na vlan10
/ip address add address=10.10.10.2/24 interface=vlan10 network=10.10.10.0CE3
# configura o hostname
/system identity set name=CE3
# cria o LAG bond1 usando LACP entre as portas ether1 e ether2
/interface bonding add lacp-rate=1sec mode=802.3ad name=bond1 slaves=ether1,ether2
# adiciona o IP /30 direto na interface bond1
/ip address add address=10.23.23.2/30 interface=bond1 network=10.23.23.0
# configura o gateway default
/ip route add gateway=10.23.23.1La configuración de los PE incluye las interfaces punto a punto, activas con OSPF, MPLS. En las interfaces de acceso, las configuraciones LAG y de sincronización e-trunk. Y en la capa de servicio, el VPLS (VSI) y la pasarela L3 (con la dirección mac y la misma IP).
PE1 – Capa central
# configura o hostname
sysname PE1
# habilita o bfd
bfd
# configura e ativa o mpls e o l2vpn
mpls lsr-id 1.1.1.1
mpls
mpls l2vpn
mpls ldp
# configura o ospf e ativa a area 0
ospf 1 router-id 1.1.1.1
opaque-capability enable
area 0.0.0.0
# configura a loopback
interface LoopBack1
ip address 1.1.1.1 255.255.255.255
ospf enable 1 area 0.0.0.0
# configura as interfaces fisicas com o /30 e ativando ospf/mpls
interface Ethernet3/0/1
description to_PE3
undo shutdown
ip address 10.1.3.1 255.255.255.0
ospf cost 1000
ospf network-type p2p
ospf enable 1 area 0.0.0.0
mpls
mpls ldp
undo dcn
undo dcn mode vlan
#
interface Ethernet3/0/2
description to_PE2
undo shutdown
ip address 10.1.2.1 255.255.255.0
ospf network-type p2p
ospf enable 1 area 0.0.0.0
mpls
mpls ldp
undo dcn mode vlanServicio MLAG y E-trunk
Aquí es donde el MLAG cobra todo su sentido. Primero creamos un Eth-Trunk ordinario, y luego lo asociamos a una configuración e-trunk, que hace que se produzca la magia MLAG.
# cria a Eth-Trunk10
interface Eth-Trunk10
mode lacp-static
lacp timeout fast
# associa a interface ao eth-trunk
interface Ethernet3/0/3
description to_CE1
undo shutdown
eth-trunk 10Con el LAG creado, ahora necesitamos crear la configuración del e-trunk. Para configurarlo, necesitamos
- de la IP del peer remoto (la sesión se cierra entre loopbacks)
- establece la prioridad entre routers (cuanto más baja, mejor)
- ajustar los temporizadores (en múltiplos de 100 ms)
- configurar la autenticación para la seguridad
- añadir una descripción al e-trunk
- configura el identificador de sistema y la prioridad del e-trunk (estos ajustes «engañan» al peer remoto para que piense que es el mismo dispositivo)
En nuestro laboratorio, vamos a cerrar el loopback entre PE1 y PE2, que forman parte del MLAG desde la perspectiva de CE1. La prioridad maestra será PE2, con prioridad 5. Los temporizadores configurados son 9 para hello y 30 para hold-timer.
# configura os parametros de system-id e prioridade do e-trunk
lacp e-trunk system-id 00e0-beba-cafe
lacp e-trunk priority 1
# cria a sessao BFD entre os peers PE1 e PE2
bfd hello bind peer-ip 2.2.2.2 source-ip 1.1.1.1
discriminator local 1
discriminator remote 2
# cria o etrunk-1
e-trunk 1
# a descricao
description PE1_to_PE2
# configura a prioridade
priority 10
# diz quais os peers da comunicacao
peer-address 2.2.2.2 source-address 1.1.1.1
# configura timers
timer hello 9
timer hold-on-failure multiplier 30
# autenticacao/senha
authentication-mode enhanced-hmac-sha256
security-key cipher %^%#dX@~~;axSXr!.(&d<4PYE)n7:!hcBBD-`2>JeFa!%^%#
# associa a sessao BFD com o e-trunk
e-trunk track bfd-session session-name helloPor último, es hora de asociar la interfaz LAG con e-trunk, creando así un MLAG desde la perspectiva de CE1.
# associa o e-trunk ao Eth-Trunk, criando assim o MLAG
interface Eth-Trunk10
e-trunk 1Servicios VPLS
# cria o VPLS chamado VPLS-1
vsi VPLS-1 static
pwsignal ldp
vsi-id 1
mac-withdraw enable
interface-status-change mac-withdraw enable
peer 3.3.3.3
ignore-ac-state
# cria a interface da vlan10 e associa o VPLS
interface Eth-Trunk10.10
vlan-type dot1q 10
l2 binding vsi VPLS-1PE2 – Capa central
Las configuraciones CORE y VPLS de PE2 son similares a las de PE1
Servicio MLAG y E-trunk
# configura os parametros de system-id e prioridade do e-trunk
lacp e-trunk system-id 00e0-beba-cafe
lacp e-trunk priority 1
# cria o lagg e associa a interface fisica de acesso
interface Eth-Trunk10
mode lacp-static
lacp timeout fast
interface Ethernet3/0/3
description to_CE1
undo shutdown
eth-trunk 10
# cria a sessao BFD
bfd hello bind peer-ip 1.1.1.1 source-ip 2.2.2.2
discriminator local 2
discriminator remote 1
# cria o etrunk1 com o PE1
e-trunk 1
priority 5
peer-address 1.1.1.1 source-address 2.2.2.2
timer hello 11
timer hold-on-failure multiplier 33
security-key cipher %^%#tv.DQ.!Y,C7ga=SnUvtMsT84Xld,eBTM\\6fSq#2%^%#
e-trunk track bfd-session session-name hello
authentication-mode enhanced-hmac-sha256
description PE1_to_PE2
# associa o e-trunk ao LAG
interface Eth-Trunk10
e-trunk 1Servicios de pasarela redundantes
Para el servicio de pasarela redundante para CE3, lo haremos:
- establecer un LAG entre PE2xCE3 y un lag entre PE3xCE3
- activar e-trunk entre PE2 y PE3 en el lag creado
- configurar los parámetros system-id y priority del e-trunk
- configura la misma dirección IP y dirección mac en la interfaz Eth-trunk de ambos routers
- añade la interfaz a OSPF
# configura os parametros de system-id e prioridade do e-trunk
lacp e-trunk system-id 00e0-beba-cafe
lacp e-trunk priority 1
# cria o LAG Eth-Trunk23
interface Eth-Trunk23
mode lacp-static
lacp timeout fast
# adiciona a interface ao LAG
interface Ethernet3/0/4
description to_CE3
eth-trunk 23
# cria a sessao BFD entre o PE2 e PE3
bfd peer_r2_r3 bind peer-ip 3.3.3.3 source-ip 2.2.2.2
discriminator local 23
discriminator remote 32
# cria o e-trunk23 entre os roteadores
e-trunk 23
priority 5
peer-address 3.3.3.3 source-address 2.2.2.2
timer hold-on-failure multiplier 30
security-key cipher %^%#tv.DQ.!Y,C7ga=SnUvtMsT84Xld,eBTM\\6fSq#2%^%#
e-trunk track bfd-session session-name peer_r2_r3
authentication-mode enhanced-hmac-sha256
description PE2_to_PE3
# associa o e-trunk ao Eth-Trunk, formando assim o MLAG
interface Eth-Trunk23
e-trunk 23
# finalmente, configura o endereçamento IP, mac e adiciona no OSPF a interface
interface Eth-Trunk23
ip address 10.23.23.1 255.255.255.252
ospf enable 1 area 0.0.0.0
mac-address 00e0-beba-cafePE3 – Capa central
Las configuraciones CORE de PE3 son similares a las de PE1.
Servicios VPLS
A diferencia de PE1 y PE2, que tienen un MLAG con el CE, en este caso la comunicación PE3xCE2 tiene lugar directamente en la interfaz física con la vlan 10. Las configuraciones VPLS siguen siendo las mismas, la diferencia está en los peers, que cierran el VPLS con PE1 y PE2 al mismo tiempo.
# cria o VPLS e adiciona os PE1 e PE2
vsi VPLS-1 static
pwsignal ldp
vsi-id 1
mac-withdraw enable
interface-status-change mac-withdraw enable
peer 1.1.1.1
peer 2.2.2.2
ignore-ac-state
# habilita a interface com o CE2
interface Ethernet3/0/3
description to_CE2
undo shutdown
# cria a interface vlan 10 e associa ao VPLS
interface Ethernet3/0/3.10
vlan-type dot1q 10
l2 binding vsi VPLS-1Servicios de pasarela redundantes
# configura os parametros de system-id e prioridade do e-trunk
lacp e-trunk system-id 00e0-beba-cafe
lacp e-trunk priority 1
# cria o LAG Eth-Trunk23
interface Eth-Trunk23
mode lacp-static
lacp timeout fast
# adiciona a interface ao LAG
interface Ethernet3/0/4
description to_CE3
eth-trunk 23
# cria a sessao BFD entre o PE2 e PE3
bfd peer_r3_r2 bind peer-ip 2.2.2.2 source-ip 3.3.3.3
discriminator local 32
discriminator remote 23
# cria o e-trunk23 entre os roteadores
e-trunk 23
priority 5
peer-address 2.2.2.2 source-address 3.3.3.3
timer hold-on-failure multiplier 30
security-key cipher %^%#tv.DQ.!Y,C7ga=SnUvtMsT84Xld,eBTM\\6fSq#2%^%#
e-trunk track bfd-session session-name peer_r2_r3
authentication-mode enhanced-hmac-sha256
description PE3_to_PE2
# associa o e-trunk ao Eth-Trunk, formando assim o MLAG
interface Eth-Trunk23
e-trunk 23
# finalmente, configura o endereçamento IP, mac e adiciona no OSPF a interface
interface Eth-Trunk23
ip address 10.23.23.1 255.255.255.252
ospf enable 1 area 0.0.0.0
mac-address 00e0-beba-cafeValidar las configuraciones y la redundancia
MC-LAG entre dispositivos
En la vista de CE1, tiene dos puertos activos en LAG bond2, siendo el puerto ether2 -que habla con PE2- el principal. El otro está listo para su uso, pero con las banderas de no reenviar tráfico.

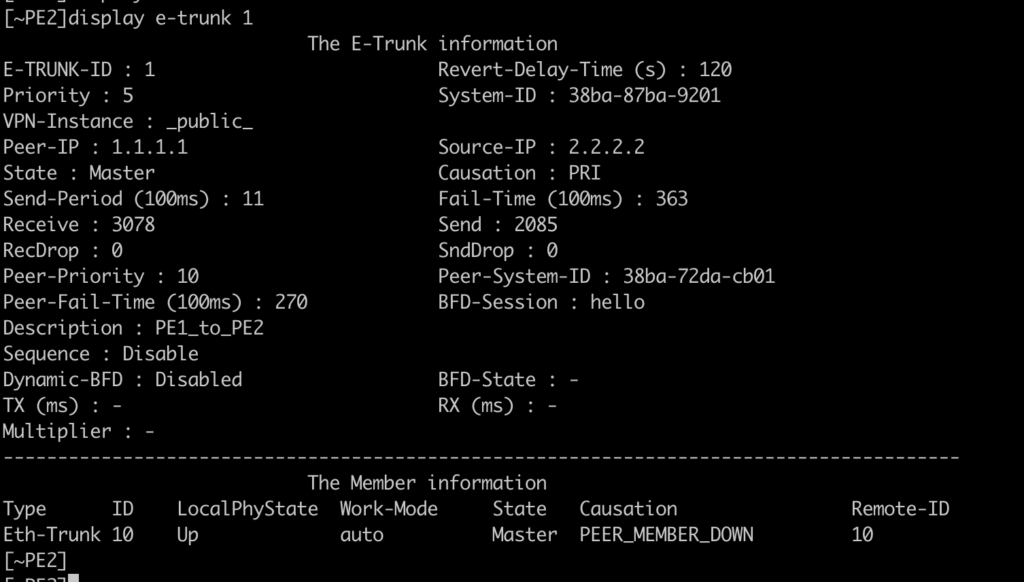
En el lado PE1, encuentra Eth-Trunk1 con el estado ARRIBA, pero el protocolo ABAJO, con la causa E-TRUNK ABAJO. Esto se debe a que MLAG está activo/respaldo, por lo que el router con peor prioridad está en estado de respaldo.

Podemos ver que en PE1, e-trunk está como copia de seguridad:

En PE2, vemos la interfaz Eth-Trunk 10 como UP. Y la interfaz Eth-trunk10.10 como UP.

Podemos ver que e-trunk está activado, y como maestro:
Servicio VPLS
Para probar el servicio VPLS, vamos:
- ping entre CEs
- valida por qué interfaz pasa el tráfico
- desactivar la interfaz principal en PE2
- comprueba que el tráfico converge inmediatamente en el otro enlace
Tráfico a través de ether2, con ping entre los CE:

Caída de la interfaz de acceso en PE2 (simulando una interrupción), y al mismo tiempo comprobación de la reconvergencia:
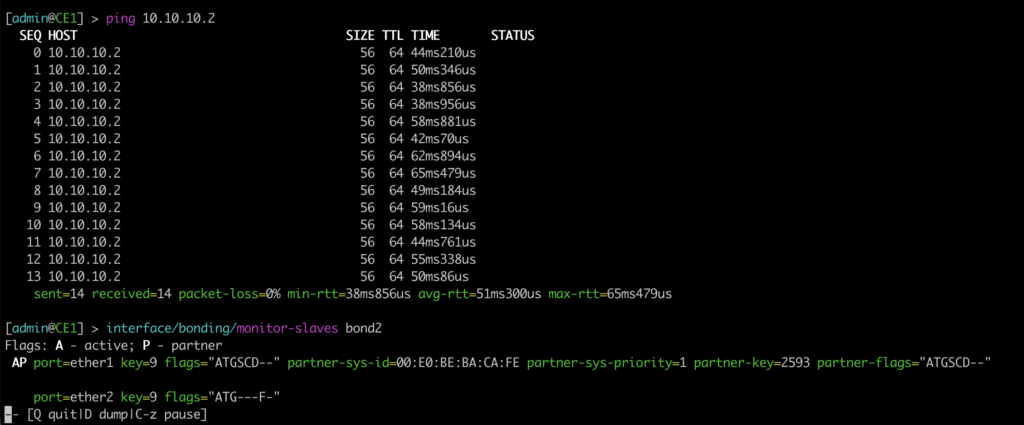
¡Prácticamente sin pérdidas! LACP/LAG simplemente cambió al enlace de e-ter1 a PE1. En este caso, el e-trunk estaba ARRIBA en PE1:
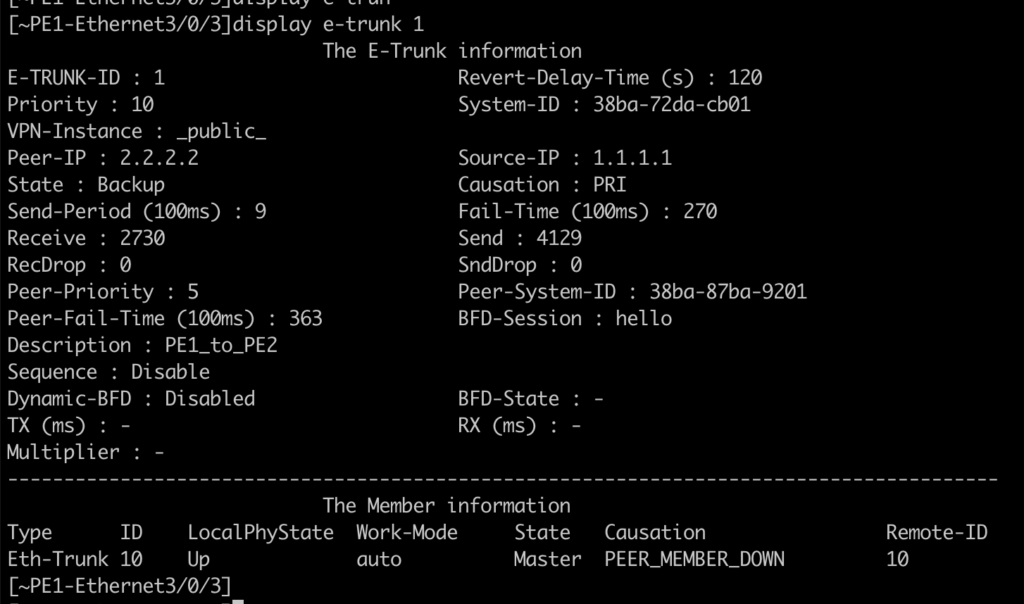
Servicio de pasarela redundante
El servicio de pasarela redundante se puede comprobar directamente en el CE3.
El puerto activo en CE3 es ether2, conectado a PE3:

Hemos hecho ping a la pasarela y también al loopback de PE1. También hemos hecho traceroute a través de PE3xPE2xPE1 (la ruta preferida debido al coste gestionado en OSPF).
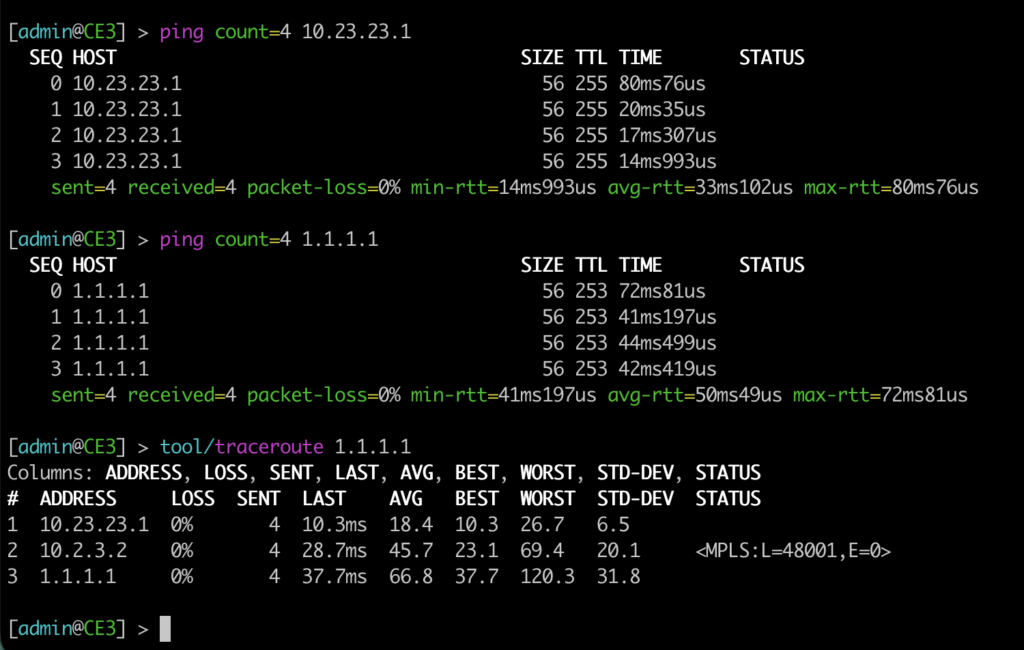
Aquí bajaremos la interfaz física en PE3, mientras al mismo tiempo se ejecuta un ping desde CE2 al loopback de PE1. Y al final vemos el cambio de traceroute.

Cambia el LACP al puerto éter1.

Estado del e-trunk en PE3 y PE2:
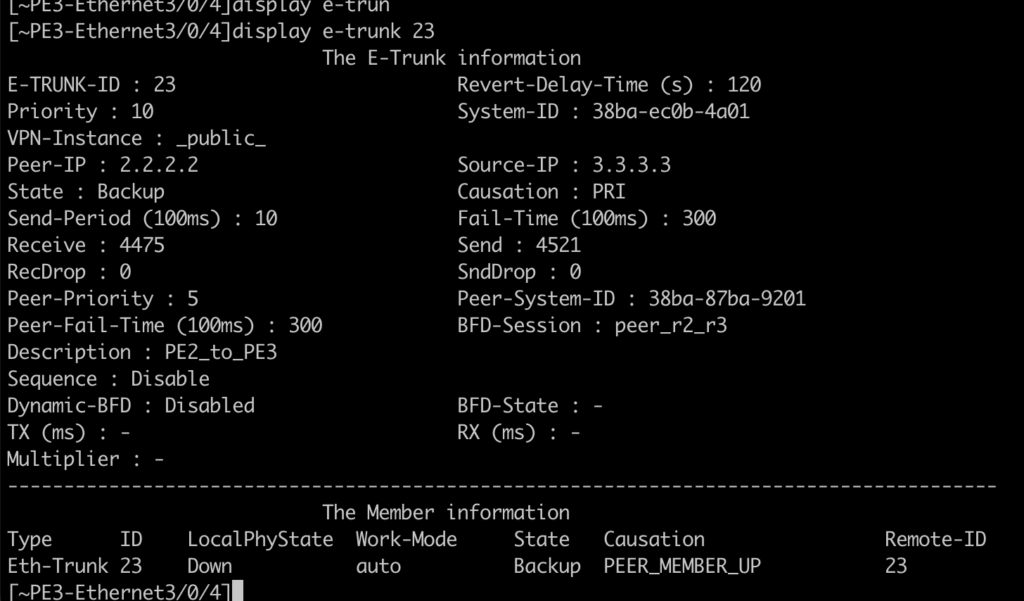
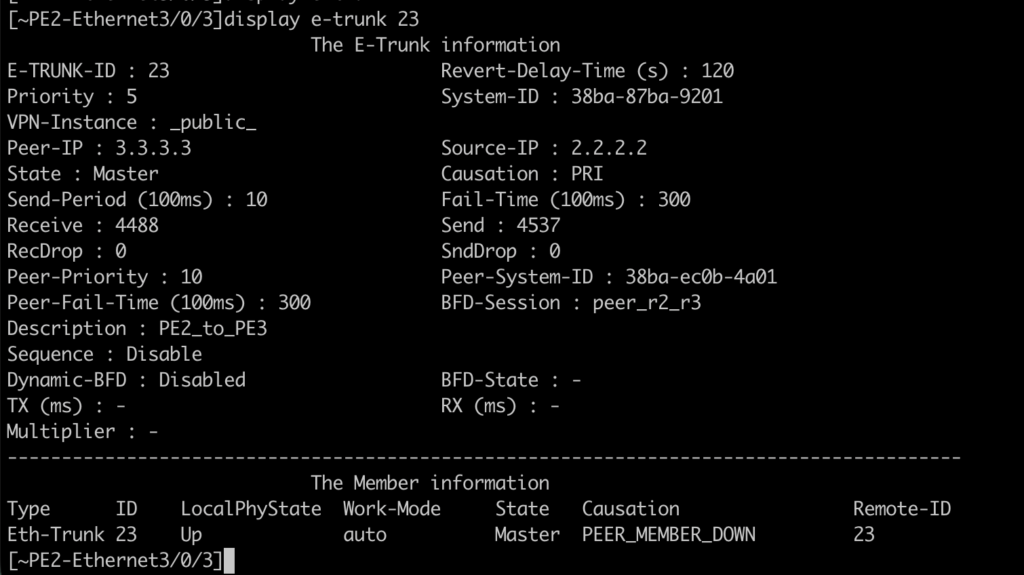
¿Y por qué esta vez no fue «tan» transparente? ¿Por qué no obtuvimos el mismo comportamiento del servicio VPLS?
La respuesta está en un nuevo elemento: el encaminamiento interno para el bloque de pasarelas. En este escenario, el router que está activo es el que genera la ruta en OSPF:
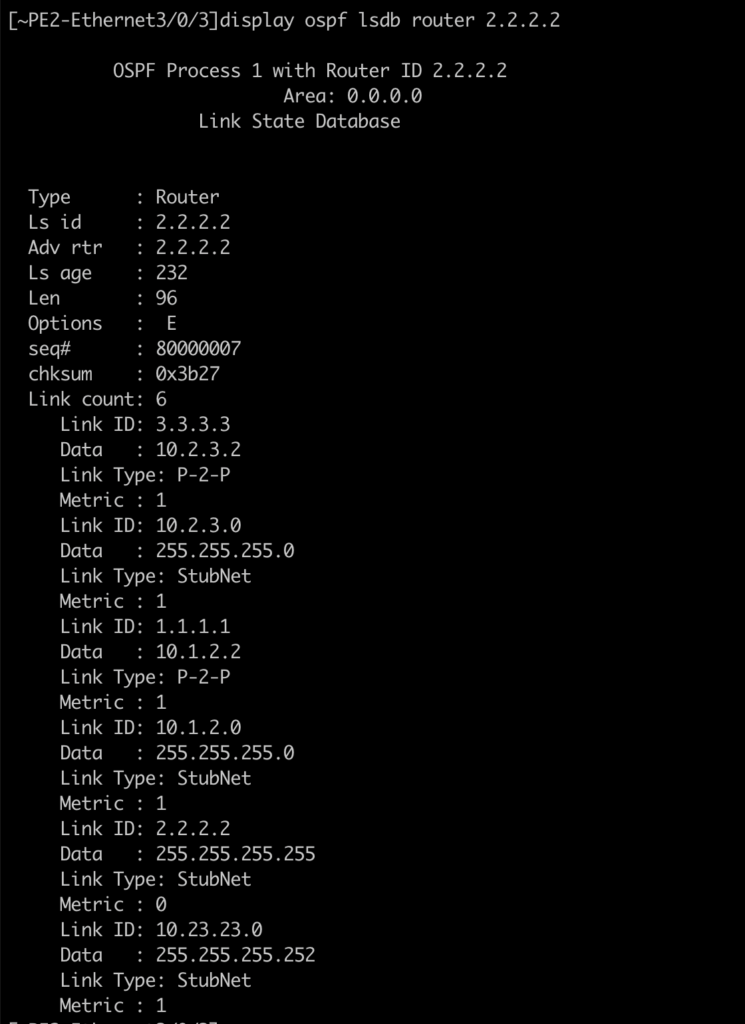
PE3, al que se le ha apagado la interfaz, no genera la ruta:

Así que, en respuesta, el retraso se debe a que, además de conmutar LACP mediante e-trunk, toda la red OSPF tuvo que recalcular la nueva ruta al nuevo router, lo que añadió unos segundos al juego (PE3 inundó la red con el LSA, haciendo caer la red 10.23.23.0/24, toda la red procesó y recalculó el SPF, y luego PE2, al reconvertir el e-trunk/lacp, volvió a generar la red 10.23.23.0/24).
Conclusiones
El MC-LAG es muy útil para garantizar la alta disponibilidad no sólo de los enlaces, sino también de los dispositivos e incluso de los POP. Ha demostrado ser viable para varios tipos de servicio, tanto L2 como L3. El protocolo e-trunk de Huawei es muy ligero y versátil, y utiliza mecanismos inteligentes como BFD para que todo sea más rápido. Su gran desventaja es que no tiene un MLAG Activo/Activo, lo que significa que uno de los circuitos (o conjunto de circuitos) estará siempre inactivo.
¿Conocías el MC-LAG? Espero que te haya gustado el artículo, y si necesitas ayuda, Made4it puede ayudarte. Somos especialistas en redes de alta disponibilidad y seguridad.
QUIERO ALTA DISPONIBILIDAD